See visuals like this from many other data creators on our Voronoi app. Download it for free on iOS or Android and discover incredible data-driven charts from a variety of trusted sources.
Key Takeaways
The Weeknd’s “Blinding Lights” is Spotify’s most-streamed song ever, with more than 5.4 billion plays as of April 2026.
Only eight songs in Spotify history have crossed four billion streams.
The ranking is dominated by English-language hits from the 2010s, when streaming became the main way people consumed music.
Spotify has reshaped how the world listens to music, but only a small group of songs have reached the platform’s highest streaming tier.
This graphic ranks the 20 most-streamed songs in Spotify history, based on official total stream counts as of the end of April 2026.
At the top is The Weeknd’s “Blinding Lights,” the only song to surpass five billion streams. Further down the list, older hits like Coldplay’s “Yellow” show how catalog tracks can continue finding new audiences decades after release.
The Toronto King of Spotify
Only one song has ever been streamed more than five billion times on Spotify: “Blinding Lights” by The Weeknd. Released in late 2019 before surging in popularity throughout 2020, the track has become the platform’s clear all-time leader.
Channeling 1980s-inspired synthpop production and a retro Las Vegas theme in its music video, “Blinding Lights” has amassed over 5.4 billion streams in just over six years since its release. It’s also the best-performing song in Billboard chart history.
The data table below highlights the top-20 most-streamed songs in Spotify history as of April 2026.
Rank
Song
Streams (#)
Year
Artist
1
Blinding Lights
5.38B
2019
The Weeknd
2
Shape of You
4.88B
2017
Ed Sheeran
3
Sweater Weather
4.55B
2013
The Neighbourhood
4
Starboy
4.49B
2016
The Weeknd, Daft Punk
5
As It Was
4.37B
2022
Harry Styles
6
Someone You Loved
4.23B
2019
Lewis Capaldi
7
Sunflower
4.21B
2018
Post Malone, Swae Lee
8
One Dance
4.18B
2016
Drake, Wizkid, Kyla
9
Perfect
3.93B
2017
Ed Sheeran
10
STAY
3.88B
2021
The Kid LAROI, Justin Bieber
11
Believer
3.82B
2017
Imagine Dragons
12
I Wanna Be Yours
3.74B
2013
Arctic Monkeys
13
Heat Waves
3.73B
2020
Glass Animals
14
lovely
3.72B
2018
Billie Eilish, Khalid
15
Yellow
3.71B
2000
Coldplay
16
The Night We Met
3.71B
2015
Lord Huron
17
Closer
3.69B
2016
The Chainsmokers, Halsey
18
BIRDS OF A FEATHER
3.66B
2024
Billie Eilish
19
Riptide
3.62B
2013
Vance Joy
20
Die With A Smile
3.62B
2024
Lady Gaga, Bruno Mars
“Blinding Lights” is not even The Weeknd’s only entry in the top-20 ranking.
“Starboy,” the title track from his third studio album, has been streamed over 4.5 billion times on Spotify, making it the fourth-most streamed song in the platform’s history. The song was a collaboration with famed French electronic music duo Daft Punk.
Anglophone Dominance
Daft Punk is the only representation from a non-Anglophone country among Spotify’s most-streamed songs.
All other songs on the list come from artists in English-speaking countries like Australia, Canada, the United Kingdom, and the United States. Anglophone artists have long benefited from the global popularity of English-language music, even among non-English-speaking audiences.
That advantage has continued in the streaming era, though artists outside the U.S. and UK have still achieved global success. Examples include Vance Joy’s “Riptide” (3.6 billion), Drake’s “One Dance” (4.2 billion), and The Kid LAROI’s “STAY” (3.9 billion).
Spotify’s Top Songs By Decade
“Yellow” by Coldplay is the only song from the 2000s to make this list, underscoring the staying power of the British band’s early hit.
Nearly three-quarters of Spotify’s most-streamed songs were released in the 2010s, when streaming became the dominant form of music consumption. This includes the top four songs on the list.
The 2020s have already produced five songs on this list, with Harry Styles’ “As It Was” becoming the most successful (4.44 billion). Meanwhile, “Die With A Smile” (3.6 billion), the 2024 collaboration between Lady Gaga and Bruno Mars, is the most recent song to reach this upper echelon of streaming success.
Learn More on the Voronoi App
To see what artists earned from these songs, check out What Artists Earn For Music Streams on Voronoi.Use This Visualization
Ethereum price remains supported by BitMine’s aggressive ETH accumulation, with the firm now controlling over 4.29% of the circulating supply and nearing its long-term 5% ownership target.
BitMine’s accumulation surge has been a significant market prop, but if the buying activity stops abruptly or, even worse, if the company defaults on liquidation during the downturn, it could cause substantial fluctuations and supply shock for ETH, caution analysts.
A rising channel pattern drives short term recovery in Ethereum price.
ETH, the native cryptocurrency of the Ethereum ecosystem, rose 0.95% during Friday’s U.S. market hours to trade at $2,312. The buying pressure gained its current momentum following the traditional U.S. stock market as indices like S&P500 and Nasdaq hit new highs. The coin price gained additional momentum from the steady buying pressure from treasury firms like BitMine. After relentless buying the company is close to its self-claimed target of owning 5% of all Ethereum in existence. Once achieved, BitMine will go silent in the accumulation of more ETH.
Origin of the Strategy
BitMine’s Ethereum obsession began on a high note. The company has closed a $250 million private placement that it used to instantly invest in ETH, doubling its stake within days of closing. Thomas “Tom” Lee, the founder of the Fundstrat, is the architect behind this and has been chairman of BitMine, the public face of the Ethereum believers.
Lee’s thesis was simple yet brave: copy the MicroStrategy Bitcoin, but this time with Ethereum. MicroStrategy’s continuous Bitcoin buying fueled its growth into what analysts described as a “sovereign put”: If a nation-state wanted to buy 5% of the Bitcoin network, it would find it easiest to purchase MSTR.
Lee said that the same could happen for ETH as it did for Bitcoin, which he called the “Wall Street put.” For any institutional level exposure to Ethereum that could be meaningful, investors<span class=”crypto-box”><span class=”crypto-name”>SHIB</span><span class=”crypto-value”>1.92%</span></span> would eventually have to go through BitMine.
The 5% Target and the Buying Machine
The number “5%” has never been a random figure. It was the tipping point that Lee and BitMine had determined their investments would become strategically significant enough for sovereign wealth funds, Wall Street institutions and nation-states to care about. Today, BitMine holds more than 4.29% of the total Ethereum circulating supply of 120.7 million tokens.
The pace of buying has been staggering. The company alone has purchased 71,524 ETH during the past week, the highest single-week purchase since December 2025. At this rate, the 5% finish line isn’t far away. It’s just a matter of weeks.
BitMine Is Becoming Ethereum’s MicroStrategy
Markets are based on supply and demand. The firm (BitMine) has been coming into the market week after week with hundreds of millions of dollars in buy orders, making it what traders call a “persistent bid,” or a known recurring buyer that sets a floor under the price.
This is no hypothetical scenario. The purchase of Bitcoin by MicroStrategy was largely responsible for setting a psychological and structural support level for BTC, during an accumulation period. For ETH, BitMine has done the same. In addition to the raw buying, BitMine also debuted MAVAN, the Made in America Validator Network, an institutional-grade staking platform.
Much of its ETH is already locked up, taken out of circulation and not available to be sold. Staking on this scale not only keeps price up, it actually constricts supply.
Ethereum’s Biggest Buyer Is About to Exit
Here is where the story gets complicated. When BitMine reaches 5% it could switch from accumulation to stewardship as per its mandate. This would present as a new challenge for the ETH market as its biggest recurring customer could suddenly vanish or slow down.
Such a pattern exists in financial markets and there’s no fun in any of the examples. The end of quantitative easing programs by central banks is almost always followed by volatility. Large rebalancing events in major index funds are correlated with stocks reverting a portion of their gains.
The mechanism is the same here. ETH’s price has somewhat factored into BitMine’s buying schedule. Once that pace slows down, the market will have to work hard to fill the demand shortfall.
BitMine May Stop Buying — But Not Sell
The bear case theory is that when people stop purchasing, they start selling. However, that’s what BitMine has indicated. The firm’s claim is that it will keep and stake — and with 5% of the supply, staking rewards are a strong financial engine.
At the current Ethereum network rates, 5% of the locked ETH will generate the passive income of hundreds of millions of dollars per year. That yield can be reinvested in the system, can be used to finance system operations, or can be returned to shareholders – all without the sale of any token.
Further, the ownership of 5% could itself become a price catalyst. According to BitMine’s thesis, once this milestone is achieved, it will become the “Wall Street put”, meaning that institutional and sovereign buyers will likely buy the BMNR stock as the best way to gain exposure to ETH, increasing demand for BMNR shares and indirectly for ETH.
BitMine’s ETH Empire Carries Systemic Risk
However, optimism must be tempered as it hasn’t been easy for BitMine. At one point during Ethereum’s 40% correction from its August 2025 peak, the company was sitting on roughly $4 billion in unrealized losses — a sobering reminder that holding 5% of an asset does not protect you from that asset’s volatility.
The hold strategy could be overcome by the pressure from the shareholders to sell the shares if the share price dips far below the NAV of BitMine’s ETH position. This is exactly what has occurred with other crypto asset treasury firms as their stock fell below NAV and their only option was to repurpose funds from crypto sales for share repurchases.
This is not going to be a soft landing for a forced BitMine as it could trigger a major supply shock for Ethereum.
Ethereum Price Drives Steady Recovery Within Channel Pattern
Since early February 2026, the Ethereum price has witnessed a steady recovery within two parallel trendlines, indicating the formation of a rising channel pattern. These two trendlines act as dynamic resistance and support for traders, driving a series of higher high and higher low in daily chart.
Currently, the Ethereum price ETH0.15%seeks stability above the $2,250 support and 50-day exponential moving average. If the support holds, the buyers could push a 10% surge to challenge the channel resistance at $2,573. A potential breakout from this barrier would further intensify the buying pressure and target $2,721 and $3,045 resistance.
ETH/USDT-1d chart
Alternatively, if the sellers continue to defend the overhead trendline, the Ethereum price may revert for another pullback and seek support at $2,150.
AI use is becoming pervasive across the legal system, with both experienced staff and absolute novices turning to ChatGPT and other tools to try to make the most persuasive case possible when they arrive in court, even if some of those claims turn out to be literally too good to be true.
Last month, top law firm Sullivan & Cromwell was forced to apologize for filing fictitious case names and fabricated quotes in a legal document submitted in a case, as well as citing incorrect statutes in the U.S. Bankruptcy Code. “We deeply regret this occurred,” the firm wrote in an apologetic letter to the judge in a case about an alleged scam operation run out of Cambodia, which the defendant denies.
It’s far from the only legal hitch blamed on AI. A 2025 High Court case in the U.K. saw a barrister submit 18 fictitious case-law citations out of 45 total. In another 2025 disciplinary case, a barrister used AI to prepare for a hearing and attempted to mask fabricated citations, while the widely publicized 2023 Mata v. Avianca case was among the first major examples of an attorney using ChatGPT to draft a legal filing that relied on entirely nonexistent judicial precedents.
The impact of AI on the legal system is also starting to come into focus through new research examining the underlying numbers. A recent study suggests that U.S. federal courts are beginning to see significant increases in their caseloads.
“The pro se share of all civil cases has been 11% for quite some time,” says Anand Shah, a researcher at the Massachusetts Institute of Technology who led the research. “And then in the post-AI world, we see it jumping all the way up to something like 18%.”
At the same time, Shah and his co-author, Joshua Levy of the University of Southern California, analyzed the proportion of AI-generated text in complaints using a random sample of 1,600 filings drawn from an eight-year period. They found that AI-generated text rose from “basically 0%” before generative AI to about 18% in early 2026. “We were just floored,” says Shah.
By digging deeper into the filings themselves, Shah and Levy found that the increase was concentrated in simpler, more templatable case types, rather than highly technical areas like patents or securities law. Shah believes that may suggest AI is helping people pursue cases they previously would not have attempted, because it has become far easier to generate the framework of a legal argument and the accompanying documents with minimal effort.
While anecdotal evidence suggests the AI influx is beginning to strain the legal system, Shah says the broader disruption has not yet fully materialized in the data. “Cases are not resolving any faster or slower, which itself is a little surprising,” he says. But he notes that the back-and-forth between opposing parties is increasing, dramatically expanding the number of filings judges must review. That number is up roughly 158%, Shah says.
Just because judges are managing to work through their expanded workloads, at least for now, doesn’t mean the system can absorb the pressure indefinitely, Shah argues. Society, he says, needs to start setting boundaries around AI in the courts before the strain becomes severe enough to slow the legal system down.
The adoption of AI isn’t entirely negative, according to Will Pearce of Orbital, a company that provides legal AI tools to the real estate sector. “There’s a complete paradigm shift, not only in legal, but just generally in terms of how society accesses and interprets information,” he says.
Pearce claims that AI has been “incredibly empowering,” opening up a legal system once dominated by dense legalese and arcane processes to people who can now use AI tools to parse documents and figure out possible next steps.
But the risks remain significant. Shah says the lower courts are already under intense strain, and warns that the pressure is likely to grow quickly as AI models improve and more people realize they can use them to generate legal filings. “I don’t think we have a lot of time,” he says.
That means more work is needed to establish rules and norms governing how and when AI should be used in the legal system. “We very much should not YOLO this transition of letting AI courts pop up willy-nilly and try a lot of stuff,” Shah warns.
Vector databases have graduated from experimental tooling to mission-critical infrastructure. In 2026, vector databases serve as the core retrieval layer for RAG pipelines, semantic search systems, and agentic AI workflows — and choosing the wrong one has real cost and performance consequences. This guide breaks down the top vector databases available today, covering architecture, performance, pricing, and the right use cases for each.
Why Vector Databases Matter More Than Ever in 2026
The shift is structural. As LLMs become standard in enterprise software, the need to store, index, and retrieve high-dimensional embeddings at scale has become unavoidable. RAG (Retrieval-Augmented Generation) has become one of the dominant architectures for grounding LLM outputs in private or real-time data, and many production RAG systems use vector databases as a core retrieval layer. The question is no longer whether you need a vector database — it is which one fits your infrastructure, scale, and budget.
RAG has become the primary use case driving vector database adoption in 2026, with RAG systems using vector databases to store document embeddings that LLMs query at inference time to generate more accurate, grounded responses. This approach has become standard infrastructure for AI applications, from customer support chatbots to enterprise knowledge management systems.
MARKTECHPOST · UPDATED MAY 2026 · 9 DATABASES REVIEWED · FACT-CHECKED AGAINST PRIMARY SOURCES
Market Size 2024
$1.97B
Projected 2032
$10.6B
CAGR
23.38%
DBs Reviewed
9
Pinecone
MANAGED
▸ Best Managed, Zero-Ops Vector DB
Pricing
Free / $20 / $50 / $500 min
Scale
Billions of vectors
CEO (Sep 2025)
Ash Ashutosh
BYOC
AWS, GCP, Azure
Strongest fully managed option for low operational overhead. New Builder tier ($20/mo) added 2026. Nexus & KnowQL launched May 2026 Launch Week.
View Pricing ↗
Milvus / Zilliz Cloud
OSS + CLOUD
▸ Best for Billion-Scale Deployments
Pricing
OSS free / Zilliz managed
Scale
100B+ vectors
GitHub Stars
40,000+ (Dec 2025)
Engine
Cardinal (10x vs HNSW)
Go-to for billion-scale with GPU acceleration. Zilliz Cloud’s Cardinal engine delivers up to 10x throughput and 3x faster index builds vs OSS alternatives.
View Pricing ↗
Qdrant
OSS + CLOUD
▸ Best Price-Performance Ratio
Free Tier
1GB RAM / 4GB disk (no CC)
Scale
Up to 50M vectors
Series B (Mar 2026)
$50M led by AVP
GitHub Stars
29,000+
Engineers’ choice. Composable vector search: dense + sparse + filters + custom scoring in one query. Rust-native. Self-host handles millions of vectors at $30–50/mo.
View Pricing ↗
Weaviate
OSS + CLOUD
▸ Best for Hybrid Search
Flex (Oct 2025)
$45/mo min (retired $25)
Plus
$280/mo (annual)
Search
BM25 + dense + filters
Free Trial
14-day sandbox
Hybrid search champion. Processes BM25, vector similarity, and metadata filters simultaneously in one query. Note: $25/mo pricing is retired since Oct 2025.
View Pricing ↗
pgvector
PG EXTENSION
▸ Best for PostgreSQL-Native Teams
Pricing
Free (open source)
Scale
Millions of vectors
Indexing
HNSW + IVFFlat
Compliance
Full ACID
If you’re on PostgreSQL and under 10M vectors, add pgvector before adding a new database. Vectors and relational data in the same transaction, zero new infrastructure.
GitHub Repo ↗
MongoDB Atlas Vector Search
MANAGED
▸ Best for MongoDB-Native Teams
Free Tier
M0 (512MB, forever)
Flex Cap
$0–$30/mo (GA Feb 2025)
Dedicated
From ~$57/mo (M10)
Indexing
HNSW, up to 4096 dims
Zero data sprawl — vectors, JSON docs, and metadata in one collection. Automated Embedding (Voyage AI) enables one-click semantic search. Integrates with LangChain & LlamaIndex natively.
View Pricing ↗
Chroma
OSS + CLOUD
▸ Best for LLM-Native Dev & Prototyping
OSS
Free (embedded / server)
Cloud Starter
$0/mo + usage
Cloud Team
$250/mo + usage
Scale
Small to medium
Fastest path from zero to working vector search. Runs in-process or as client-server. Not optimized for extreme production scale — purpose-built for LLM application scaffolding.
View Pricing ↗
LanceDB
OSS + CLOUD
▸ Best for Serverless & Multimodal Retrieval
Pricing
OSS free / Cloud & Enterprise
Storage
S3, GCS (file-based)
Format
Lance columnar (on-disk)
Modalities
Text, images, structured
Sits directly on object storage — no always-on server. AWS-validated for serverless stacks at billion-vector scale. Strong multimodal support for cross-modal retrieval pipelines.
GitHub Repo ↗
Faiss (Meta AI)
LIBRARY
▸ Best for Research & Custom Pipelines
Pricing
Free (open source)
Type
Library, not a database
GPU
Supported (CUDA)
Indexes
IVF, HNSW, PQ, IVFPQ
A library, not a database — no persistence, query API, or operational tooling. The foundation many production systems build on. For ML researchers and custom similarity search pipelines.
GitHub Repo ↗
Comparison at a Glance
Database
Type
Best Scale
Managed
Pricing Start
Key Strength
Pinecone
SaaS
Billions
Yes
Free / $20 / $50 min
Zero-ops, agentic AI
Milvus / Zilliz
OSS + Cloud
100B+ vectors
Optional
OSS free / Zilliz mgd
GPU acceleration, scale
Qdrant
OSS + Cloud
Up to 50M
Optional
Free tier (1GB RAM)
Price-perf, composability
Weaviate
OSS + Cloud
Large
Optional
$45 Flex min
Native hybrid search
pgvector
PG Extension
Millions
Via PG
Free
PostgreSQL unification
MongoDB Atlas
Managed SaaS
Millions
Yes
M0 free / Flex $0–$30
Doc + vector in one DB
Chroma
OSS + Cloud
Small–Med
Yes
OSS free / Cloud $0+
Developer experience
LanceDB
OSS + Cloud
Small–Large
Yes
OSS free
Serverless / multimodal
Faiss
Library
Any (custom)
No
Free
Research, GPU search
How to Choose in 2026
EDITOR’S ECOSYSTEM PICK
MongoDB Atlas Vector Search
Already running MongoDB? You don’t need a second database.
Atlas Vector Search keeps operational data, metadata, and vector embeddings in one collection — no sync lag, no dual-write, no extra billing envelope. Automated Embedding via Voyage AI adds one-click semantic search. Flex tier caps at $30/month. M0 free tier available with no credit card.
Type: Fully managed SaaS | Built in: Proprietary Rust engine | Best for: Startups and enterprises prioritizing speed-to-market
Pinecone remains one of the strongest fully managed options for teams that want low operational overhead. Its serverless architecture allows developers to store billions of vectors without provisioning a single server, with strong multi-tenant isolation and high-availability SLAs.
In 2025–2026, Pinecone optimized its serverless architecture to meet growing demand for large-scale agentic workloads. Key capabilities include Pinecone Inference (hosted embedding and reranking models integrated into the pipeline), Pinecone Assistant for production-grade chat and agent applications, Dedicated Read Nodes (DRN) for read-heavy workloads, and native full-text search in public preview. BYOC (Bring Your Own Cloud) — now in public preview on AWS, GCP, and Azure — runs the data plane inside the customer’s own cloud account. Pinecone also launched Nexus and KnowQL in early access as part of its May 2026 Launch Week.
Pricing: Pinecone has four tiers: Starter (free), Builder ($20/month flat), Standard ($50/month minimum usage), and Enterprise ($500/month minimum usage). The Builder tier is new in 2026, targeting solo developers and small teams. At production scale, costs can climb significantly — but the zero-DevOps overhead justifies it for teams without dedicated infrastructure engineers.
Community Sentiment: G2 reviewers consistently praise Pinecone for low-latency similarity search, managed scalability, and developer-friendly APIs — the recurring theme is time saved on infrastructure rather than raw performance. One reviewer noted switching from AWS OpenSearch specifically to cut costs, and found Pinecone’s serverless tier dramatically cheaper at their scale. The primary complaint is cost predictability: pricing climbs fast on Standard and Enterprise tiers, and several practitioners flag the lack of granular scaling controls as a friction point. Overall G2 sentiment is positive, with users in fintech, legal AI, and document Q&A workflows citing it as the lowest-friction path from prototype to production.
Milvus / Zilliz Cloud — Best for Billion-Scale Deployments
Milvus is the dominant open-source choice for billion-scale deployments. Its managed counterpart, Zilliz Cloud, uses Cardinal — a proprietary vector search engine that Zilliz says delivers up to 10x higher query throughput and 3x faster index building compared to open-source HNSW-based alternatives — with native integration with streaming data platforms like Kafka and Spark.
Milvus is designed for efficient vector embedding and similarity searches, supporting GPU acceleration, distributed querying, and efficient indexing. It is highly configurable and supports a range of indexing methods such as IVF, HNSW, and PQ, allowing users to balance accuracy and speed according to their needs. The database offers excellent scalability with efficient index storage and shard management.
In distributed mode, Milvus introduces additional operational dependencies — including metadata storage, object storage, and WAL/message-log infrastructure — depending on the deployment configuration. For most teams, it is more infrastructure than the workload demands.
Community Sentiment: Reddit’s own engineering team ran a head-to-head evaluation of Milvus vs. Qdrant on approximately 340 million Reddit post vectors at 384 dimensions using HNSW (M=16, efConstruction=100) — and chose Milvus, citing better scalability, organizational fit, and operational comfort, even though Qdrant had a performance edge in certain filtered query benchmarks. The community consensus is that Milvus is overkill for teams under 50 million vectors but becomes the clear choice once distributed scale, heterogeneous node types, and tiered storage matter. Zilliz Cloud’s Cardinal engine is increasingly cited in benchmark discussions as a meaningful step up from open-source HNSW, and resolves the most common complaint about self-hosted Milvus: operational complexity.
Qdrant — Best Price-Performance Ratio
Type: Open-source + managed cloud | Built in: Rust | Best for: Performance-critical RAG, self-hosting, edge deployment
Its 2026 differentiator is composable vector search: every aspect of retrieval is a composable primitive engineers control directly — indexing, scoring, filtering, and ranking are all tunable, none opaque. Operators can compose dense vectors, sparse vectors, metadata filters, multi-vector retrieval, and custom scoring in a single query.
Qdrant offers the best price-performance ratio in 2026. Self-hosted on a small VPS, it handles millions of vectors at $30–$50/month.
The free tier provides 1GB RAM and 4GB disk storage with no credit card required. Paid cloud plans are resource-based rather than a flat fee — pricing scales with compute and storage provisioned. Filtering is where Qdrant stands out — the database supports rich JSON-based filters that integrate with vector search efficiently. Choose Qdrant when you’re budget-conscious, need complex filtering at moderate scale (under 50 million vectors), want edge or on-device deployment via Qdrant Edge, or want a solid balance of features without breaking the bank.
Community Sentiment: AI Professionals describe Qdrant as a Rust-native, simple-ops database with strong filtering that delivers great small-to-mid scale latency — and community sentiment consistently rewards it for being the easiest dedicated vector database to self-host. The Reddit engineering evaluation found Qdrant faster on filtered queries at constant throughput but noted higher interaction between ingestion load and query load compared to Milvus. On X and Reddit, Qdrant is frequently recommended for legal AI and financial compliance tools where metadata filtering depth matters more than raw throughput. Several AI Professionals also noted subsequently migrating from Pinecone to reduce costs.
Weaviate is the hybrid search champion in 2026, delivering native BM25 + dense vectors + metadata filtering in a single query. Built-in vectorization via integrated embedding models eliminates external pipelines. Multi-modal support handles text, images, and audio in the same vector space.
While Pinecone and Milvus focus on pure vector search, Weaviate does one thing better than any other database in this comparison: hybrid search. You query with a vector embedding, add keyword filters using BM25, and apply metadata constraints — Weaviate processes all three simultaneously and returns ranked results. Other databases add these features separately or require combining separate queries; Weaviate builds it into the core architecture.
The modular architecture lets teams swap in different embedding models, vectorizers, and rerankers without rebuilding an application — critical when models update frequently.
Pricing: Weaviate restructured its cloud pricing in October 2025. The old Serverless tier ($25/month) was retired and replaced with Flex at $45/month minimum (shared cloud, 99.5% SLA, pay-as-you-go), along with from $280/month (annual commitment, 99.9% SLA), and Premium from $400/month (dedicated infrastructure, 99.95% SLA). A free 14-day sandbox is available with no credit card required, but it expires automatically and cannot be extended. Any source still citing $25/month is referencing pre-October 2025 pricing.
Community Sentiment: AI Professionals reviews note that Weaviate’s built-in vectorization modules — which handle embedding generation inline — call the same external APIs teams would call in their own application code, so the convenience comes with less pipeline control and additional API latency and cost. The GraphQL API also draws criticism for its learning curve compared to REST or SQL interfaces, and the Java-based runtime is flagged as resource-intensive for self-hosting. That said, engineers building knowledge graph-enriched search find Weaviate the most natural fit, and the BM25 + vector + filter in one query capability is the feature most cited as the reason teams stay on Weaviate rather than migrating to a simpler alternative.
pgvector — Best for PostgreSQL-Native Teams
Type: PostgreSQL extension | Best for: Teams wanting a unified relational + vector data stack
The most significant trend in current architecture is the growing adoption of pgvector. If you are already using PostgreSQL, you likely don’t need a new database. It has pushed its capacity to millions of vectors with production-grade speed. It offers full ACID compliance for both traditional relational and vector data.
pgvector adds a vector column type to PostgreSQL with support for cosine similarity, L2 distance, and inner product operations. It supports both HNSW and IVFFlat indexing.
The operational advantage is significant: vectors live next to relational data, both can be queried in the same transaction, and teams manage one system instead of two. For applications where vector search is one feature among many — rather than the core workload — this is often the right call.
Community Sentiment: The 2026 practitioner consensus is consistent: for most backend teams already on PostgreSQL, pgvector is the simplest path — documents and embeddings in the same table, same transaction, filtered using SQL, with no sync pipeline, no extra credentials, and no new service to monitor. Production reviewers recommend it confidently for workloads under 5–10 million vectors, with caveats around HNSW index build times and memory pressure at larger scales. On Reddit and Hacker News, pgvector has become the default “try this first” recommendation, increasingly displacing Chroma in that role for teams with an existing PostgreSQL footprint.
MongoDB Atlas Vector Search — Best for MongoDB-Native Teams
Type: Fully managed SaaS (Atlas) | Best for: Full-stack applications where vectors must live alongside JSON documents and operational data
MongoDB Atlas Vector Search brings vector retrieval directly into the Atlas managed database platform — eliminating the “data sprawl” problem of maintaining a separate vector store alongside a primary database. Operational data, metadata, and vector embeddings all live in the same collection, queryable in a single pipeline. This is the strongest argument for MongoDB in the vector space: zero synchronization lag between document updates and their vector index.
Atlas Vector Search uses HNSW-based ANN indexing and supports embeddings up to 4,096 dimensions, with scalar and binary quantization for cost and performance optimization. Search Nodes allow teams to scale their vector search workload independently from their transactional cluster — critical for read-heavy RAG applications. The platform integrates natively with LangChain, LlamaIndex, and Microsoft Semantic Kernel, and supports RAG, semantic search, recommendation engines, and agentic AI patterns out of the box.
A standout 2026 feature is Automated Embedding — a one-click semantic search capability powered by Voyage AI that generates and manages vector embeddings automatically, without requiring teams to write embedding code or manage model infrastructure.
Atlas Vector Search is integrated into Atlas cluster pricing — there is no separate charge for the vector search feature itself. The M0 tier is free forever (512MB storage). The Flex tier (GA February 2025) supports Vector Search and caps at $30/month, replacing the older Serverless and Shared tiers. Dedicated clusters start at approximately $57/month (M10) for production workloads.
Community Sentiment: MongoDB’s official benchmark against the Amazon Reviews 2023 dataset showed that at 15.3 million vectors using voyage-3-large embeddings at 2048 dimensions, Atlas Vector Search with scalar or binary quantization retains 90–95% accuracy with under 50ms query latency — shifting community perception from “adequate” to genuinely competitive for mid-scale RAG. Practitioner sentiment on Reddit skews positive for teams already in the MongoDB ecosystem, where the zero-sprawl argument (one database, one billing envelope, zero sync lag) resonates strongly. The MongoDB 8.0 series release also introduced up to 45% faster queries on large datasets, which teams running both document and vector workloads cite as a compounding benefit. The primary criticism: Atlas Vector Search only makes sense if you already have operational data in Atlas — it may not be the right choice for teams coming to MongoDB specifically for vector search.
Chroma — Best for Prototyping and LLM-Native Development
Type: Open-source, embedded or client-server | Best for: Early development, local prototyping, LLM application scaffolding
Chroma is an open-source embedding database focused on developer experience. It runs in-process (embedded) or as a client-server setup, making it the fastest path from zero to a working vector search.
Chroma has an intuitive API that simplifies integration into applications, making it accessible for developers and researchers without requiring extensive database management expertise. It delivers high accuracy with impressive recall rates, supporting embedding-based search and advanced ANN (Approximate Nearest Neighbor) methods.
Chroma DB’s combination of simplicity, flexibility, and AI-native design makes it an excellent choice for developers working on LLM-powered applications. Its open-source nature and active community contribute to its rapid evolution.
Chroma Cloud is available with a Starter plan ($0/month + usage), Team plan ($250/month + usage), and Enterprise custom pricing — meaning Chroma is no longer purely self-hosted.
Community Sentiment: Production level AI professionals who have deployed Chroma across legal AI, financial compliance, and educational products describe it as genuinely production-ready despite its dev tool reputation — with a single 4–8GB VPS handling millions of embeddings comfortably. PeerSpot highly ranks Chroma in the vector databases category, though its mindshare has declined from 15.6% to 13.4% year-over-year as pgvector absorbs teams that prefer staying on a single service. The community recommendation in 2026 is consistent: Chroma for new RAG projects and prototypes, but you may plan for a migration path to Qdrant or pgvector once filtering requirements grow or dataset size crosses a few million records.
LanceDB — Best for Serverless, Object-Storage-Backed, and Multimodal Retrieval
Type: Open-source + cloud/enterprise | Best for: Serverless functions, object-storage-backed deployments, multimodal AI pipelines
LanceDB is an open-source, serverless vector database that stores data in the Lance columnar format, designed to sit directly on object storage (S3, GCS, etc.) without requiring an always-on server. AWS specifically calls out LanceDB as well-suited for serverless stacks because it is file-based and integrates natively with S3 — enabling elastic, pay-per-query retrieval at billion-vector scale with no persistent infrastructure to manage.
LanceDB’s columnar format enables fast random access and efficient filtering directly on-disk, avoiding the memory overhead that most other vector databases require at query time. It also has strong multimodal support, making it relevant for pipelines that work across text, images, and structured data.
Community Sentiment: LanceDB’s mindshare has grown from 6.7% to 9.6% year-over-year, the steepest growth rate among all databases in this comparison, driven by rising interest in serverless and multimodal AI architectures. AI professionals on X and in the LangChain and LlamaIndex communities cite LanceDB most often for image + text pipelines and agent memory stores where the Lance columnar format’s on-disk efficiency outperforms in-memory alternatives. The main community caveat is the relative immaturity of the managed cloud tier compared to Pinecone or Weaviate.
Faiss (Meta AI) — Best for Research and Custom Pipelines
Type: Open-source library (not a full database) | Best for: Research, custom similarity search, GPU-accelerated batch workloads
Faiss‘s combination of speed, scalability, and flexibility positions it as a top contender for projects requiring high-performance similarity search capabilities. When working with Faiss, best practices include choosing the appropriate index type based on dataset size and search requirements, experimenting with parameters like nlist and nprobe for IVF indexes, and using GPU acceleration for significant performance boosts on large datasets.
It is important to note that Faiss is a library, not a full database system. It handles indexing and search but does not provide persistence, a query API, or operational tooling out of the box. It is the foundation many production systems build on, not a drop-in replacement for the databases above.
Community Sentiment: PeerSpot rates Faiss a little lower than others with a notably declining mindshare — from 17.8% to 9.2% year-over-year in the vector databases category — reflecting a broad shift away from library-level tooling toward full database systems with persistence, APIs, and operational tooling. One senior software engineer highlighted its seamless integration with the Colbert model via the Ragatouille framework, citing improved retrieval accuracy at token-level embedding granularity — a use case where Faiss still has no direct competitor. The community in 2026 treats Faiss less as a production database choice and more as a research primitive: the go-to for GPU-accelerated batch similarity search in custom pipelines, but not a system most teams would deploy directly in a production RAG application without significant custom infrastructure wrapping it.
Feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us
The post Best Vector Databases in 2026: Pricing, Scale Limits, and Architecture Tradeoffs Across Nine Leading Systems appeared first on MarkTechPost.
The company behind the second-largest stablecoin by market cap has successfully raised $222 million in the presale of a token tied to its new blockchain called Arc.
The fully diluted valuation has risen to $3 billion, while company CEO Jeremy Allaire hinted that the firm will also enter into the “apps business.”
The Q1 results press release from Circle informed that the USDC in circulation grew 28% during the first quarter of the year and reached $77 billion. More impressively, the USDC on-chain transaction volume jumped by over 260% to $21.5 trillion. The total revenue and reserve income in Q1 of $694 million showed an increase of 20%.
The $222 million presale raise at a $3 billion fully diluted network valuation saw participation by many industry and legacy giants, including ARK Invest, BlackRock, Bullish, Intercontinental Exchange, SBI Ground, and Standard Chartered Ventures.
The white paper for the upcoming asset, ARC Token, went live today and reportedly outlines how “a native coordination asset could support governance, security, and network operations” on the Arc blockchain.
“We’re entering the operating system business, and we’re doing it by building this multi-stakeholder distributed model with a token, with a distributed network … and we’re also getting into the apps business,” CEO Allaire told CNBC.
The chief exec added that the launch of the company’s Agent Stack will build trusted infrastructure for “AI-native economic activity and a more programmable internet financial system.”
Circle’s stock price (CRCL) is up by over 2% in pre-market activity. Recall that the shares rocketed by 20% last week after two US senators announced a bipartisan compromise of the most contentious issues regarding the highly anticipated stablecoin deal.
The post BlackRock Bets on Circle’s Arc: $222M Raised in Major Token Presale appeared first on CryptoPotato.
US President Donald Trump on Sunday branded Iran’s terms for ending the Middle East war “totally unacceptable,” raising the likelihood of renewed conflict after weeks of negotiations. Iran had responded to Washington’s latest peace proposal earlier in the day, while warning it would not hold back from retaliating against any new US strikes or permit more foreign warships in the Strait of Hormuz.
With sentiment starting to bounce and infrastructure building, nascent signals from corporation executives as well on-chain data are helping sketch out Bitcoin’s potential course of action.
Whether it is the more aggressive accumulation tactics or subtle changes to mining behaviors, the ecosystem is setting itself up in a game theoretic posture that will be less speculative and much much more fundamental.
Strategy Strengthens Commitment to Long-Term Bitcoin Holding
Public comments from the Executive Chairman of Strategy, Michael Saylor, reinforced Microstrategy’s ongoing long-term commitment to Bitcoin. Saylor claims Strategy will never be a net seller of Bitcoin. Instead, the company aims to accelerate its accumulation campaign and will aim for buying back 10-20 Bitcoins against each one sold. This strategy highlights a core goal, which is to maximize Bitcoin / share exposure. This pledge is more than just rhetoric; it is a calculated monetary tactic. Strategy, thanks to maintaining a high ratio of constant accumulation, seeks the maximum value from the long-term growth of BTC at least in a directional sense and using its own terms for it.
Michael Saylor has said "never sell your Bitcoin" for years – but in this exclusive interview at Consensus in Miami, he told me why that's changing. Watch Now pic.twitter.com/AmZJvZFflm
— The Wolf Of All Streets (@scottmelker) May 10, 2026
Pocketing Profits Without Slowing Down The Rate Of Gain
A more nuanced dimension of Strategy, as Saylor elaborates. The company plans to incrementally sell some of its Bitcoin holdings, not as a departure away from its fundamental beliefs, but offsetting cash flow coming up short for dividend payments associated with the new STRC preferred share offering.
Which introduces a novel hybrid that retains the power to capture Bitcoin price appreciation but with a strong accumulation bias rather than all out aggressive monetization. Instead of liquidating assets for short term gain, Strategy puts Bitcoin into productive use, providing yield without losing overall exposure for the long haul.
Such an evolution signals a mature framework of sufficiently institutional Bitcoin that creates bail leverage not merely as a store of value but also as an intermediary cash flow management tool to collateralize structured products and shareholder-driven financial returns.
New Purchases Bring Further Market Speculation
Saylor’s latest social media activity has fueled speculation. A “Back to work” post, complemented by a fresh orange Bitcoin tracker, flocked observers to expect another round of purchases on the part of Strategy.
These signals are being watched closely by analysts and investors for confirmation This timing stacks up with Bitcoin being deep within 2021 accumulation levels, described by institutional players as both very likely an important area for accumulated stock to flow from and especially appealing for staking bullish extrapolation in the longer time frames.
Market commentary from Scott Melker. These are historically important signals ahead of material buying initiatives by Strategy, simple cues to track for those watching institutional flows.
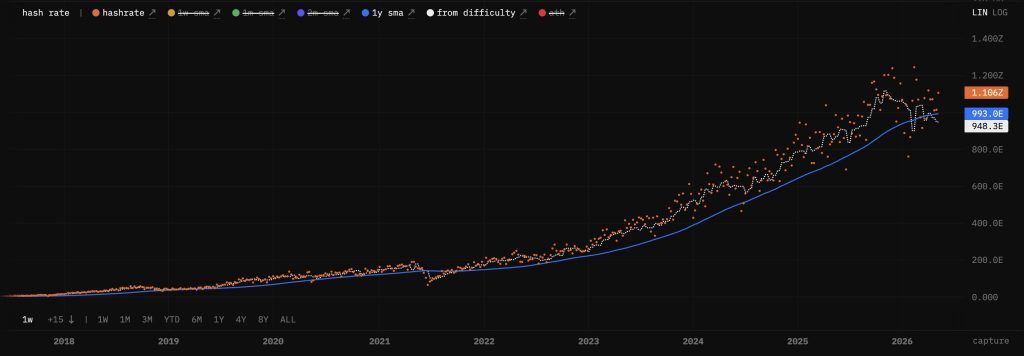
Bitcoin Hashrate Falls Under Yearly Average
Though we still observe strong overall corporate accumulation, there is a more subtle shift in miner behaviour evident on-chain.
According to a new report from CryptoQuant analyst Darkfost, Bitcoin’s network hashrate dropped below its annual average for the first time since 2021 recently, an important inflection point.
The last event happened during the China Cryptocurrency Mining Crackdown followed by a large reallocation of hash-rates worldwide.
But current conditions have none of the deregulatory shock associated with that period. Instead, it seems declines reflect an industry correction cycle. Competition is rising, and margins are under pressure, leading miners to reassess their operations.
For further analysis, see Darkfost analysis on hashrate trends
The hashrate has fallen back below its yearly average.
The last time mining activity dropped enough to move below its annual average was during the China cryptocurrency mining crackdown in 2021.
There is nothing dramatic about this for Bitcoin, but since the winter storm in… pic.twitter.com/fSfDP00kLx
A drop in hashrate doesn’t equal weakness for the network. Instead, it points to intensifying competition in the mining industry.
With new entry and energy prices in constant motion, the difficulty to enable profitability over time has become exceptionally high. Absorption is being driven by the closure of less efficient, less competitive facilities by some operators as well as corporate structural adjustment in response to changed market conditions.
Bitfarms recent announcement of some strategic changes to increase operational efficiency is an example of this trend. These types of moves indicate an accelerating sectoral evolution, where only the fittest of the fittest miners are likely to survive. Other external shocks (e.g., February winter storms in the United States) have contributed to mining production bottlenecks and further complicated operations.
Network Mechanics Are On The Way To Equilibrium
While there is some short-term volatility, Bitcoin’s protocol can guarantee its long-term stability. The network tries to produce blocks every 10 minutes regardless of how much mining is going on.
Hash rate decreases can cause block times to lengthen. This is an ongoing process, but every 2,016 blocks mining difficulty is re-evaluated to bring the balance back.
One of Bitcoin’s strongest features is its resistance, the same automatic adjustment that allows dynamic adjustment based on participation changes to ensure network continuity and security during transitions. As of now, hashrate sits beneath 1 ZH/s as the network continues to find a new operating baseline. This step is expected and necessary as miners reposition their businesses to the changing economic conditions.
A State Of Growth And Adaptation In The Market
These movements show a market both consolidating and transforming.
Hodling from institutions like Saylor has both conviction and creativity in financial ways. At the same-time, the mining sector is adjusting to new realities of intensifying competition and emerging cost structures.
This dual dynamic is far from signalling weakness, in reality it’s a highly resilient ecosystem. Bitcoin is now maturing not just as a digital property but also as one global network of which the participants are becoming an increasingly sophisticated class.
As Strategy likely gears up for further acquisitions and miners adjust to the new normal, this week could offer key signals regarding the next phase of Bitcoin growth.
Disclosure: This is not trading or investment advice. Always do your research before buying any cryptocurrency or investing in any services.
Follow us on Twitter @nulltxnews to stay updated with the latest Crypto, NFT, AI, Cybersecurity, Distributed Computing, and Metaverse news!
China has announced that it will not allow Taiwan to participate in the upcoming annual assembly of the World Health Organization, intensifying an ongoing diplomatic dispute over Taiwan’s international status. The meeting of the World Health Assembly is scheduled to begin next week, and the decision has once again highlighted the deep political divisions surrounding […]
The post China Blocks Taiwan From WHO Assembly Amid Diplomatic Rift appeared first on Modern Diplomacy.
Federal prosecutors say a former Pennsylvania bank manager stole more than $214,000 from a Citizens Bank branch and spent most of the money feeding a gambling habit, a scheme that has now landed him in federal prison.
Jonathan Lim, 42, of Wallingford, was sentenced this week to 18 months behind bars followed by five years of supervised release after pleading guilty to bank fraud and bank embezzlement charges. Prosecutors said Lim took approximately $214,155 while serving as branch manager of the Citizens Bank location on West Lancaster Avenue in Downingtown.
Delco Man Sentenced to 18 Months in Prison for Stealing More Than $214,000 From the Bank Where He Worked @FBIPhiladelphia https://t.co/YkLUxdmf0f
Court records filed May 6 and seen by ReadWrite show U.S. District Judge Michael M. Baylson imposed concurrent 18-month prison terms on both counts. Lim was also ordered to repay Citizens Bank the full amount investigators said was stolen.
Authorities said Lim worked at the Citizens Bank “Thorndale branch” from June through November 2019. Along with managing the branch, he also performed teller duties during that period.
Investigators trace gambling losses to Pennsylvania bank ATM operations
Federal prosecutors said Lim became the branch ATM coordinator on July 30, 2019, putting him in charge of ATM cash operations and the weekly audits tied to balancing the machine.
Investigators alleged that Lim accessed the ATM roughly 59 times between July and November 2019. Authorities said he manipulated records to hide missing cash by falsifying settlement worksheets connected to ATM balancing procedures.
The indictment also alleged that Lim directed coworkers to sign paperwork “without telling those persons that the worksheets contained false information.” Prosecutors said those records were later used to conceal shortages connected to the ATM.
Federal authorities further alleged that Lim removed cash from the ATM and temporarily kept it inside a locked area of the bank vault that was under his control. Investigators said he later removed the money from the bank without documenting the withdrawals.
The theft was discovered shortly after Lim resigned from Citizens Bank in November 2019. According to the U.S. Attorney’s Office, an audit performed two days later revealed that the ATM was missing more than $178,000. Investigators also found an additional shortage of about $36,000 connected to Lim’s teller cash box.
Court documents stated that the ATM contained only about $13,435 during the audit, which was roughly $178,155 less than internal records showed should have been there.
Federal prosecutors said the total loss to Citizens Bank reached approximately $214,155. The sentencing order requires Lim to pay restitution in that same amount.
The Justice Department said Lim spent “the majority of the money gambling.”
As part of his supervised release conditions, Lim cannot work “in the banking industry or in any position of fiduciary responsibility,” according to court filings.
The FBI investigated the case, and Assistant U.S. Attorney Mark B. Dubnoff handled the prosecution.
Featured image: Canva
The post Pennsylvania bank manager imprisoned after stealing funds to support gambling habit appeared first on ReadWrite.

 Ed Sheeran
Ed Sheeran The Neighbourhood
The Neighbourhood

 The Weeknd, Daft Punk
The Weeknd, Daft Punk





![Official Trump [TRUMP]](https://novaastrax.com/wp-content/uploads/2026/05/TRUMP-memecoin-team-moves-49mln-tokens-–-Can-23-still-640x360.jpg "TRUMP memecoin team moves 4.9mln tokens – Can $2.3 still")




 The hashrate has fallen back below its yearly average.
The hashrate has fallen back below its yearly average.