Italian producer Lorenzo Gangarossa, whose credits include Pawel Pawlikowski’s upcoming Cannes competition title “Fatherland,” is set to join Lucky Red as head of international projects of the Rome-based indie that was recently acquired by France’s Canal+ Group. The move signals the intent on the part of Lucky Red, a leading Italian indie film distributor that […]
LayerZero Labs acknowledged a Lazarus Group attack on internal RPCs and a multisig signer’s unauthorized personal trade, impacting 0.36% of assets on the protocol.
Scaling large language models (LLMs) is expensive. Every token processed during inference and every gradient computed during training flows through feedforward layers that account for over two-thirds of model parameters and more than 80% of total FLOPs in larger models. A team researchers from Sakana AI and NVIDIA have worked on a new research that directly targets this bottleneck — not by changing the architecture, but by making the computation inside feedforward layers significantly cheaper through unstructured sparsity.
Sparsity Exists, But GPUs Ignore It
Inside a transformer’s feedforward block, for any given input token, only a small fraction of hidden neurons actually fire — the rest produce zero after passing through the activation function. This is called activation sparsity, and prior work has documented this phenomenon in models with ReLU activations.
The frustrating reality is that this theoretical savings rarely translates into actual speedups. NVIDIA GPUs are heavily optimized for dense matrix multiplications using Tensor Cores, which operate on large contiguous tiles of data. Traditional sparse formats like ELLPACK (ELL) require a separate kernel pass to convert activations from dense to sparse representation, and that conversion overhead often cancels out what’s saved by skipping the zeros.
Critically, prior work on sparse LLM kernels (including TurboSparse, ProSparse, and Q-Sparse) has focused on memory-bound GEMV operations — the single- or few-token inference regime. The research team instead targets compute-bound GEMM operations in the batched setting with thousands of input tokens, where dense baselines on modern devices can execute orders-of-magnitude higher FLOP/s with large tiles and Tensor Cores. That is a fundamentally harder problem, and the reason prior approaches didn’t generalize to batched training or high-throughput inference.
Sparser, Faster, Lighter LLMs — TwELL & Sparse CUDA Kernels
Sakana AI × NVIDIA — arXiv:2603.23198 — ICML 2026
01 — The Problem
Feedforward layers dominate LLM cost — and most of that work is wasted.
> ⅔
of all model parameters live in feedforward layers
80%+
of total FLOPs consumed by feedforward layers
99%+
of hidden activations can be zero with no accuracy drop
For any given token, only a tiny fraction of hidden neurons actually fire. The rest output zero after the activation function. This is called activation sparsity — and it has historically been impossible to exploit on modern GPUs because sparse operations ran slower than dense ones.
Prior sparse LLM kernels (TurboSparse, ProSparse, Q-Sparse) only targeted single-token GEMV operations. Sakana AI and NVIDIA tackle the harder problem: batched GEMM with thousands of tokens — the regime that covers both training and high-throughput inference.
02 — The Innovation
TwELL: a sparse format built around how GPU kernels actually work.
Old Way — ELL
Row-wide packing, costly to build
Standard ELLPACK packs non-zeros row-by-row across the entire matrix. To construct it from a tiled matmul output you need a separate kernel launch, a full global memory read, and synchronization across all CTAs. Those overheads cancel out the savings from skipping zeros.
New Way — TwELL
Tile-wise packing, built in the epilogue
TwELL partitions columns into horizontal tiles matching the matmul kernel’s tile size T_n. Non-zeros are packed locally within each tile. By matching dimensions, TwELL is constructed inside the existing gate projection kernel epilogue — no extra kernel, no extra memory read, no synchronization overhead.
The inference pipeline uses one fused kernel that reads gate activations in TwELL format and performs up + down projections together. The intermediate hidden state is never written to global memory, cutting DRAM traffic at every forward pass.
For training, a hybrid sparse format dynamically routes rows into a compact ELL matrix (sparse rows) or a dense backup (overflow rows). Sparsity during training is highly non-uniform — max non-zeros per row can be orders of magnitude above the average — so the hybrid design handles this without becoming brittle.
03 — Training Recipe
Two changes to your training config. Nothing else.
01
Replace SiLU with ReLU as the gate activation function. ReLU produces exact zeros for negative inputs — this is what enables unstructured sparsity. No other architectural change is needed. (Unregularized ReLU sits slightly below SiLU on task accuracy: 46.4% vs 47.1% on the 1.5B model, offset by the efficiency gains.)
02
Add an L1 loss term on the hidden feedforward activations, averaged over all tokens and hidden dimensions across all layers. Recommended coefficient: L1 = 2×10⁻⁵. Add it to your standard cross-entropy loss. No changes to learning rate, weight decay, batch size, or optimizer.
03
Sparsity stabilizes fast. The non-zero count settles within ~1,000 training steps (~1B tokens). The training kernels deliver memory and throughput benefits for almost the entire training run, not just toward the end.
Watch Out
At L1 = 2×10⁻⁵, over 30% of neurons become permanently inactive (dead neurons) on average across layers. Downstream accuracy is not visibly affected at this level. The paper explores targeted gate weight reinitialization as a mitigation — yielding +19.1% speedup vs +17.9% baseline with no accuracy cost.
04 — Benchmark Results
Accuracy preserved. Efficiency scales up with model size.
Model
Accuracy
Inference
Energy / tok
Training
Peak Mem
0.5B
40.4% → 40.4%
+17.0%
−11.8%
−1.5%
−19.2%
1B
44.6% → 44.7%
+18.1%
−14.6%
+7.1%
−25.5%
1.5B
46.4% → 46.2%
+18.8%
−15.0%
+11.6%
−28.1%
2B
49.1% → 48.8%
+20.5%
−17.0%
+21.9%
+22.3% *
All results at L1 = 2×10⁻⁵ on a single node of eight H100 PCIe GPUs, sequence length 2048. Efficiency gains grow with scale — average non-zero activations drop from 39 (0.5B) to 24 (2B), giving the sparse kernels proportionally more computation to skip. * The 2B sparse model uses a larger micro-batch enabled by reduced activation memory, raising peak usage while improving throughput.
05 — Key Findings
What the paper reveals about where sparsity actually lives.
◆
Early layers are least active. In a 28-layer 1.5B model, the first two layers have the fewest non-zero activations. Activity peaks in the early-to-middle layers — consistent with prior work showing LLM reasoning and knowledge retrieval concentrate there.
◆
First tokens in a sequence fire far more neurons. The model allocates exponentially more computation to early sequence positions where contextual cues from prior tokens are absent. This non-uniformity is exactly what the sparse kernels exploit for speedups.
◆
Strong inverse correlation between sparsity and speedup. The paper measures a Pearson correlation of −0.996 between each layer’s average non-zero count and its inference speedup contribution. Sparser layers deliver proportionally larger gains.
◆
Larger gains on less specialized hardware. On NVIDIA RTX PRO 6000 (188 SMs vs 114 on H100), training speedups are significantly higher. Dense GEMM is slower on the RTX 6000, while sparse ops run faster — widening the relative advantage of sparsity on accessible hardware.
06 — Get Started
Open-source. All kernels and training code released.
■
Architecture: Works with gated feedforward LLMs — Llama, Qwen, and any Transformer++ design. Non-gated (original transformer) variant also supported: 11.2% inference speedup vs 17.9% for gated at the same L1.
■
Hardware: CUDA kernels written for H100 GPUs using TMA-based pipelining and persistent cooperative design. Gains verified on RTX PRO 6000 with even larger speedups.
■
Existing models: Fine-tuning via sparsification approaches is flagged as a future direction for bringing these kernels to pretrained dense models — not yet demonstrated in this paper.
(function () {
var STEPS = [
{ label: ‘Problem’ },
{ label: ‘Innovation’ },
{ label: ‘Recipe’ },
{ label: ‘Results’ },
{ label: ‘Findings’ },
{ label: ‘Start’ }
];
var cur = 0;
var nav = document.getElementById(‘mtp-twell-nav’);
var panels = document.querySelectorAll(‘#mtp-twell .tw-panel’);
var prevBtn = document.getElementById(‘mtp-twell-prev’);
var nextBtn = document.getElementById(‘mtp-twell-next’);
var counter = document.getElementById(‘mtp-twell-counter’);
/* Build nav pills */
STEPS.forEach(function (s, i) {
var pill = document.createElement(‘div’);
pill.className=”tw-step-pill”;
pill.setAttribute(‘data-i’, i);
var btn = document.createElement(‘button’);
btn.className=”tw-step-btn”;
btn.innerHTML =
‘‘ + (i + 1) + ‘‘ +
‘‘ + s.label + ‘‘;
btn.addEventListener(‘click’, function () { go(i); });
pill.appendChild(btn);
if (i < STEPS.length – 1) {
var line = document.createElement('div');
line.className = 'tw-step-line';
pill.appendChild(line);
}
nav.appendChild(pill);
});
function go(n) {
cur = Math.max(0, Math.min(STEPS.length – 1, n));
/* pills */
var pills = nav.querySelectorAll('.tw-step-pill');
pills.forEach(function (p, i) {
p.classList.remove('active', 'done');
if (i === cur) p.classList.add('active');
else if (i 44) go(dx < 0 ? cur + 1 : cur – 1);
}, { passive: true });
go(0);
})();
So, What Exactly is Proposed
The research team addresses this mismatch with two primary contributions: a new sparse data format called TwELL (Tile-wise ELLPACK), and a set of custom CUDA kernels for inference and training built around it.
TwELL is designed around one key insight: modern matmul kernels already divide computation across small 2D tiles (of size T_m × T_n) assigned to individual cooperative thread arrays (CTAs). Standard ELL packs non-zeros row-by-row across the entire matrix, which requires global synchronization to construct from tiled matmul outputs. TwELL instead partitions the columns of the gate activation matrix into horizontal tiles of size T, and within each tile stores non-zero values and their indices in a local ELL-style layout. By matching the tile dimension T to the column tile size T_n of the matmul kernel, TwELL can be produced directly in the epilogue of the gate projection kernel — no extra kernel launch, no additional global memory read, no synchronization across CTAs. The format uses a compression factor C such that T/C exceeds the maximum non-zeros per tile, and packages values, indices, and non-zero counts into a single 32-bit matrix for locality.
For inference, a single fused kernel takes the gate activations in TwELL format and performs the up and down projections together. Each CTA handles one row of inputs, iterating first statically over column tiles and then dynamically over each tile’s non-zero count. For each active neuron at index n, the CTA loads the n-th column of the up projection weight matrix W_u and the n-th row of the down projection weight matrix W_d, computes the dot product, and accumulates into the output. The intermediate hidden state h_u is never materialized in global memory, cutting DRAM traffic significantly.
For training, the situation is more complex because sparsity patterns are highly non-uniform across tokens and layers — the maximum non-zeros per row can be orders of magnitude above the average, making a pure ELL layout brittle. The research team introduces a hybrid sparse format that dynamically routes rows either into a compact ELL matrix (for rows below a non-zero threshold) or into a dense backup matrix (for overflow rows). This allows efficient sparse gradient computation in the backward pass without requiring dense-to-dense matmuls for most rows. The team also releases kernels for the original non-gated transformer feedforward block; at the recommended sparsity level, the non-gated variant achieves an 11.2% inference speedup compared to 17.9% for the gated design.
Just ReLU and L1 Regularization
The sparsity induction strategy is deliberately minimal. The research team used ReLU as the gate activation function and add a simple L1 loss term on the hidden feedforward activations, controlled by a coefficient L1. No other architectural changes are required, and the research team reported that adding L1 regularization did not affect other hyperparameters (learning rate, weight decay, optimizer settings).
Models were trained on the fineweb dataset (a deduplicated fineweb-edu split) at chinchilla-optimal token counts — approximately 10B tokens for a 0.5B model up to 40B tokens for a 2B model — with a context length of 2048 and a batch size of 1M tokens.
Testing eight L1 coefficient values on a 1.5B parameter model, they find that up to L1 = 3 × 10−5, there is essentially no drop in mean task accuracy across seven downstream benchmarks (ARC Easy/Challenge, HellaSwag, OpenBookQA, PIQA, WinoGrande, CommonsenseQA), with final cross-entropy increasing by less than 2% relative to the unregularized baseline. The recommended setting L1 = 2 × 10−5 reduces average non-zero activations from 911 per layer (in the unregularized 1.5B model with a feedforward hidden dimension of 5632) down to just 29 — roughly 99.5% sparsity — with no measurable downstream performance loss.
One important key point: at L1 = 2 × 10−5, over 30% of neurons become permanently inactive (dead neurons) on average across layers. The research team explores two mitigation strategies — scheduling the L1 warmup and applying targeted reinitialization to dead gate projection columns — and finds that the reinitialization approach maintains similar sparsity levels while slightly improving both downstream accuracy and efficiency (+19.1% inference speedup vs. +17.9% baseline). This is listed as a direction for future work.
Measured Efficiency Gains
The efficiency results are reported on a single node of eight H100 PCIe GPUs, with a fixed sequence length of 2048 tokens. For the cross-scale comparison, the L1 coefficient is fixed at 2 × 10−5.
At smaller scales, sparsity delivers clear peak memory reductions during training:
Model
Dense Peak Memory
Sparse Peak Memory
Change
0.5B
26.2 GB
21.2 GB
−19.2%
1B
44.5 GB
33.1 GB
−25.5%
1.5B
62.8 GB
45.1 GB
−28.1%
At 2B parameters, the sparse model uses a larger micro-batch (enabled by reduced activation memory at that scale), which results in higher peak GPU memory (46.7 → 57.1 GB) but faster training throughput (+21.9%). The efficiency gains on all metrics for the 2B model:
Training step throughput: 22.4 → 27.3 input tokens/ms (+21.9%)
Across the full 0.5B–2B range, mean task accuracy of sparse and non-sparse models remains statistically indistinguishable. Efficiency benefits grow with model scale: larger models naturally develop lower average non-zero counts (dropping from 39 at 0.5B to 24 at 2B), which means the sparse kernels skip a proportionally greater share of computation.
Training speedups are also observed on NVIDIA’s RTX PRO 6000 GPU, where the larger Streaming Multiprocessor count (188 vs. 114 on H100) allows sparse operations to run faster — suggesting these gains extend to less specialized hardware.
What the Sparsity Patterns Reveal
Sparsity is not uniform: the first two layers of a 28-layer 1.5B model are the least active, followed by a pronounced peak in non-zero activations across early-middle layers — consistent with prior work suggesting this is where much of LLM reasoning and knowledge retrieval occurs. Separately, the first tokens in an input sequence activate far more neurons than later tokens, with an exponential decrease thereafter. The research team observed an inverse Pearson correlation of −0.996 between each layer’s average non-zero count and its inference speedup contribution, confirming that the sparsest layers provide the greatest per-layer gains.
Check out the Paper, Repo and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us
The post Sakana AI and NVIDIA Introduce TwELL with CUDA Kernels for 20.5% Inference and 21.9% Training Speedup in LLMs appeared first on MarkTechPost.
As part of a series profiling the expected Round 1 sides for all 17 NRL clubs in 2026, the pressure is on coach Todd Payten to get the Cowboys living up to their potential.
It is quite simple for Todd Payten – he needs to get the Cowboys shooting up the ladder or he will be no chance of getting a contract extension.
Get that fairytale lifetime-guarantee-on-all-repairs kind of care. Book at one of our 275 locations nationwide, online or call 13 13 28. T&Cs apply.
Heading into the final year of his deal, Payten’s Cowboys have missed the finals in the past two seasons despite having several representative stars on their roster.
More League
NRL Round 1 Predicted Teams: North Queensland Cowboys – Make or break for Payten with serial under-performers
Hunt’s on the prowl for another contract as veteran star confirms Broncos spine shake-up
Round 1 Predicted Teams: Roosters – Robinson hoping history repeats with DCE firing up new-look Chooks
NRL random predictions: Panthers bite back, Bellamy finally retires, Dolphins leap into finals and Maroons win Origin
How do you solve a problem like Fifita? Bennett’s biggest challenge will be lighting a fire under fading star
League
Payten needs to find the right combinations with his team selections and fix their leaky defence to have any hope of remaining at the helm.
Here’s how their team is shaping up for Round 1.
Who’s new?
The addition of Reed Mahoney after he was told he was free to negotiate elsewhere by the Bulldogs is the only signing of note for the Cowboys heading into their 2026 season.
But the fact that he is replacing an Origin standard hooker in Reece Robson means that, on paper, it’s a net loss for North Queensland.
Young fullback Ethan King has made the long trek north from the Roosters after being stuck behind James Tedesco while ex-Panther Soni Luke gives Payten an extra dummy-half option, likely as a back-up to Mahoney.
Veteran journeyman Matt Lodge has lobbed at his sixth NRL club but the 30-year-old is no longer an impactful prop while ex-Dolphins second-rower James Walsh gives them a potential bench forward candidate.
Reed Mahoney. (Photo by Daniel Pockett/Getty Images)
Who’s gone?
Robson’s decision to defect to the Roosters was a bitter blow after the Cowboys turned him into an Origin player.
Former Kangaroos prop Jordan McLean has retired, utility forward Karl Lawton is now with Hull KR and outside back Semi Valemei has also headed to the Super League, lining up with Castleford.
Tom Duffy has ditched the Cowboys for the Broncos after getting limited opportunities at halfback last season while Emarly Bitungane is spending a season at Catalans before becoming a foundation member of the Perth Bears roster.
Key spots to unlock?
Tom Dearden made the transition to halfback for Queensland after game one last year and Payten followed suit at club level with the co-captain wearing the No.7 jersey for the second half of the season.
Jake Clifford finished the year as his halves partner but the Cowboys have high hopes for rising star Jaxon Purdue becoming a difference maker at five-eighth and he is a strong chance to start the season alongside Dearden.
Payten also has question marks out wide with Viliami Vailea, Zac Laybutt, Tom Chester, Braidon Burns and Robert Derby in the mix for the wing and centre berths with automatic selection Murray Taulagi.
Cowboys coach Todd Payten. (Photo by Ian Hitchcock/Getty Images)
With Coen Hess suspended and Griffin Neame and Jeremiah Nanai sidelined with injury to start the season, the Cowboys are no sure things to knock over wooden spooners Newcastle in Las Vegas on March 1.
If Lodge is required for the season opener, he will have to get an exemption due to his well-documented assault charges from a decade ago in New York City.
Round 1 predicted team
1 Scott Drinkwater 2 Viliami Vailea 3 Zac Laybutt 4 Tom Chester 5 Murray Taulagi 6 Jaxon Purdue 7 Tom Dearden 8 Jason Taumalolo 9 Reed Mahoney 10 Thomas Mikaele 11 Heilum Luki 12 John Bateman 13 Reuben Cotter Interchange 14 Jake Clifford 15 Sam McIntyre 16 Kai O’Donnell 17 Harrison Edwards 18 Robert Derby 19 Braidon Burns
Other squad members: Coen Hess (suspended), Griffin Neame, Jeremiah Nanai (injured), James Walsh, Jaxson Paulo, Kaiden Lahrs, Mason Kira, Matt Lodge, Zac Herdegen
Bitcoin ETFs saw an inflow of $623 million in the last week. This inflow marks six straight weeks of strong investor demand.
Ethereum, XRP and SOL also saw inflows after previous week’s (April 27 to May 1) outflows.
Rising ETF inflows and steady price gains indicate that there is growing confidence in the broader crypto market.
In the first week of May 2026, the cryptocurrencies have seen a huge interest from investors through spot exchange-traded funds (ETFs). These ETFs let people buy crypto without having to deal with wallets or exchanges.
Last week, from May 4 to May 8, 2026, data from SoSoValue showed strong net inflows across Bitcoin, Ethereum, XRP and Solana spot ETFs. This signals growing confidence amid rising prices. Bitcoin’s ETF alone managed to bring in $623 million, while total assets hit record highs.
Bitcoin Spot ETFs: BlackRock Dominates with Record Inflows
Bitcoin spot ETF had an amazing week. The ETF products saw an inflow of $623 million, as per SoSoValue. This number also means that more money poured in than it flowed out, which pushed holdings of these products. Moreover, with this inflow, Bitcoin ETFs have now marked six straight weeks of steady investor demand.
Total Bitcoin Spot ETF History Data
The star performer was BlackRock’s ETF IBIT, which saw a weekly net inflow of $596 million. That is more than 95% of the total weekly gains for Bitcoin ETFs. IBIT’s total weekly gains for Bitcoin ETFs. IBIT’s total historical net inflow now stands at an impressive $66.10 billion.
Then there is Ark & 21 Shares ETF ARKB, with a solid weekly net inflow of $53.09 million. ARKB’s cumulative historical net inflow has reached $1.71 billion.
On the contrary, not every ETF product managed to gain. Grayscale Bitcoin Trust GBTC saw the largest net outflow. The product saw $62.28 million flowing out. This number also indicates that investors are moving to cheaper options such as IBIT.
As of now, the total net asset value of all Bitcoin spot ETFs is $106.61 billion. The ETF net asset ratio, which is nothing but how much of Bitcoin‘s market is held buy these ETFs, sits at 6.67%. Overall, historical net inflows for Bitcoin ETFs total $59.34 billion.
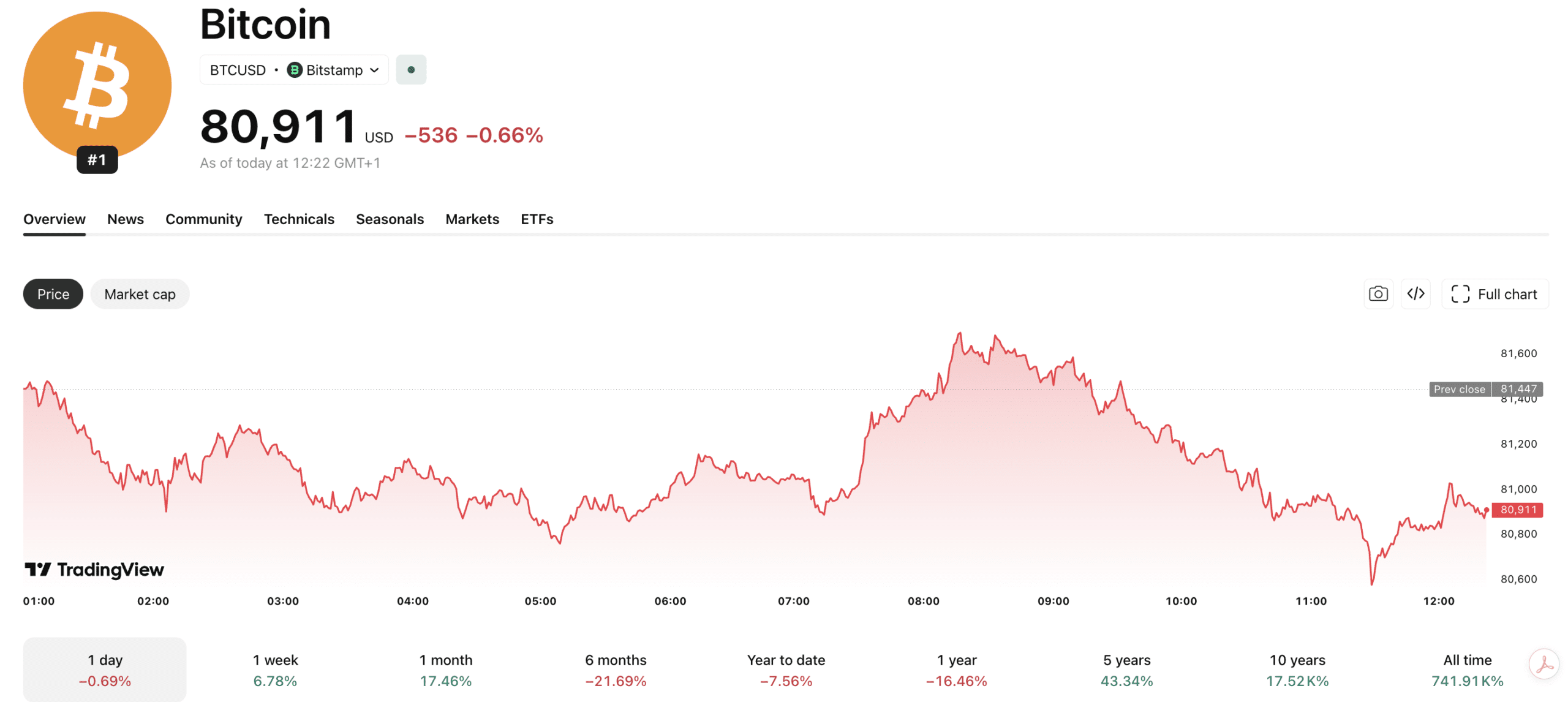
As institutional money flowed into these ETF products, the price of the token has also increased. At press time, the price of the BTC0.14%token stands at $80,833.60 with an uptick of 0.1% in the last 24-hours as per CoinGecko. Moreover, earlier today, the token price touched $82,342, hinting at more upside if inflows continue.
BTC 24-hours chart
Ethereum Spot ETFs Gain Momentum Despite Mixed Flows
Ethereum spot ETFs also posted positive numbers. The products managed to bring in $70.49 million last week, as per SoSoValue. This comes as Ethereum’s ecosystem grows with DeFi apps and layer-2 solutions. After a week of outflows from April 27 to May 1, Ethereum ETFs bounced back with fresh positive inflows.
Total Ethereum Spot ETF History Data
BlackRock’s ETF ETHA led the pack and it managed to bring in $100 million in weekly net inflows. ETHA’s total historical net inflows now hit $12 billion, this also indicates a stronghold in crypto ETFs.
Grayscale’s Ethereum Mini Trust ETH came in second, as the product saw $6.3257 million in weekly net inflows. Its cumulative historical net inflows total $1.94 billion, a bright spot for Grayscale after Bitcoin struggles.
Fidelity’s ETF FETH did not follow the same trend. The product saw the biggest outflow of the week, which was $32.1563 million. Still, FETH’s overall historical net inflows stand at $2.26 billion, so it is not out of the game.
As of now, Ethereum spot ETFs have a total net asset value of $13.73 billion which is 4.49% of Ethereum‘s total market cap. Cumulative historical net inflows have reached $12.09 billion.
At press time, the price of the ETH0.29% token stands at $2,338.91 with an uptick of 0.5% in the last 24-hours as per CoinGecko. Moreover, earlier today, the price of the token hit $2,379.
ETH 24-hours chart
XRP Spot ETFs See Steady Inflows
Just like Ethereum, XRP ETF products also saw one week of negative inflows from April 27 to May 1, following three straight weeks of positive inflows, before rebounding with renewed inflows last week (from May 4 to May 8). The XRP ETF products saw an inflow of $34.21 million in the said period as per SoSoValue.
Total XRP Spot ETF Data
Canary ETF XRPC topped the list with $13.5393 million in weekly net inflows. XRPC’s total historical net inflows is now $438 million, building a strong base. Bitwise ETF XRP followed closely, with $12.3621 million weekly net inflows and $434 million in total historical inflows. These two funds captured most of the action. As of press time, XRP spot ETFs’ total net asset value is $1.120 billion. The ETF net asset ratio is 1.26%.
At press time, the price of the XRP1.91% token stands at $1.45 with an uptick of 2.5% in the last 24-hours as per CoinGecko. Moreover, the price of the XRP token hit $1.50 yesterday.
XRP 24-hours chart
Solana Spot ETFs Break Out with Strong Weekly Gains
Solana spot ETFs recorded $39.23 million in net inflows last week from April 27 to May 1, as per SoSoValue. The Bitwise ETF BSOL managed to bring in $36.3915 million weekly. BSOL’s total historical net inflow is $862 million.
Total SOL Spot ETF Data
Fidelity ETF FSOL added $2.8399 million weekly, with historical net inflows at $161 million. Together they drove most of Solana’s ETF momentum.
Currently, Solana spot ETFs hold $987 million in net assets. The ETF net asset ratio is 1.82%, showing ETFs are carving out a bigger role. Cumulative historical net inflows are $1.060 billion.
At press time, the price of the token stands at $95.28 with an uptick of 1.9% in the last 24-hours as per CoinGecko.
SOL 24-hours chart
Final Thoughts
The ETF flows indicate that there is a growing confidence in crypto, with bitcoin leading the charge. Bitcoin ETFs brought in $623 million, showing strong institutional demand, while BlackRock’s IBIT remains dominant with $66.10 billion in historical inflows.
Ethereum added $70.49 million, indicating that the interest is beyond Bitcoin. XRP and Solana also saw steady inflows of $34.21 million and $39.23 million respectively. Prices also stayed positive, with Bitcoin hovering around $80,000, Ethereum at $2,300, XRP at $1.45 and SOL at $95.
Overall, Bitcoin is still dominating the crypto ETF space, Ethereum, XRP and Solana ETF activity still suggests that the investors are also moving their money into other cryptocurrencies as well. The prices of the said tokens could also increase if the ETF inflows continue.
Also Read: Bitcoin ETFs Pull $46.3M, Extend Inflow Streak to 5 Days
Bitcoin slipped back below $80,000 today (May 8), as fresh US military strikes in the Strait of Hormuz drained risk appetite across markets, pushing BTC to $79,250, a -2.8% decline in 24 hours. The retreat snaps a multi-day green streak that had carried the asset to $82,700 earlier this week. Whether the six-week winning run survives the weekend depends on one question: Will Iran respond or negotiate?
The proximate trigger was a reported new round of US strikes in the Strait of Hormuz, which rattled broader equity markets and prompted traders to trim exposure to speculative assets. BTC had briefly touched $82,000 on the back of $2.44Bn in April ETF inflows, the strongest monthly figure since October 2025.
That momentum has now stalled. Earlier episodes in this conflict showed Bitcoin reacting sharply to ceasefire deterioration, and Friday’s price action fits that pattern uncomfortably well.
The broader crypto market has fallen -1.2%, tracking the total crypto market cap sitting at $2.73 trillion, with risk-off sentiment extending across altcoins. The macro picture remains binary: a credible peace signal could reignite the rally, while further escalation threatens a deeper technical breakdown.
(SOURCE: TradingView)
Can the BTC USD Price Hold $78,900 and Reclaim $83,000 This Week?
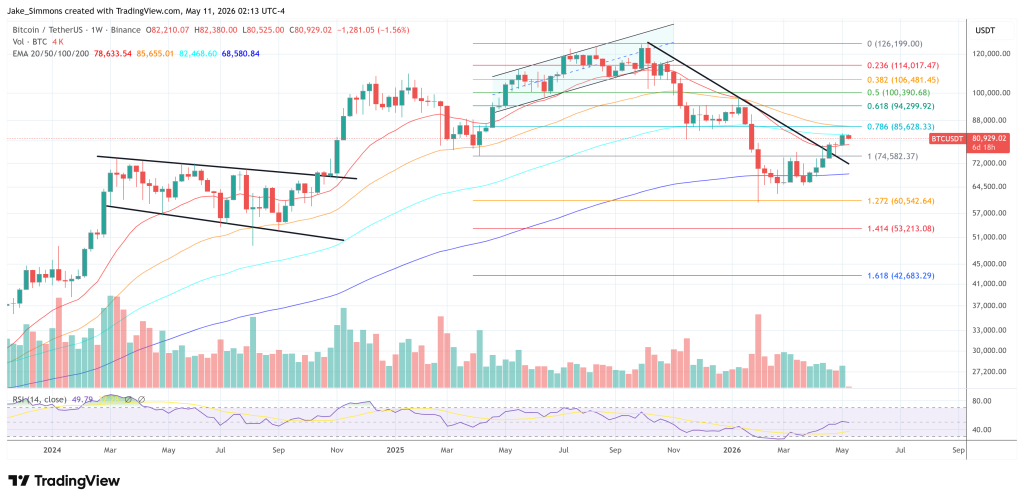
At $79,381.69, Bitcoin is pressing against a cluster of technical floors that analysts had flagged well before Friday’s drop. The immediate line in the sand sits at the 50% Fibonacci retracement level of $78,920; a breach there would expose the 100-day EMA near $75,886, a level not tested since the earlier phase of the Iran conflict. BTC’s reaction to ceasefire news earlier in the cycle showed how quickly the $72,000 range came into play once macro support evaporated.
On the upside, MEXC analysts identify the 200-day moving average at $83,000 as the pivotal resistance — a clean close above that level would open a path toward $89,000–$94,000 and potentially $100,000 if ETF demand remains consistent through mid-May. RSI sits at 65.60, technically still bullish but cooling after the short-squeeze spike faded.
Three scenarios deserve attention:
Bull case: Iran signals genuine ceasefire progress over the weekend, BTC reclaims $81,000 Monday, and ETF flows resume, $85,000 by mid-May appears plausible under that reading.
Base case: Stalemate persists, BTC consolidates between $78,900 and $81,000 as markets await the next catalyst.
Bear case: Escalation deepens, $78,920 fails, and a retest of the $75,886 EMA becomes the more probable outcome. The six-week winning streak is technically intact, but it is hanging on to geopolitics rather than fundamentals.
DISCOVER: Best crypto to buy right now – CoinSpeaker’s updated guide
Bitcoin Hyper Targets Early-Mover Upside as Bitcoin Tests Key Levels
For investors watching Bitcoin stall at resistance with macro risk overhead, the math on further spot upside at an $1.6 trillion market cap looks increasingly compressed. The asymmetric return window sits earlier in the stack.
That is the thesis behind Bitcoin Hyper ($HYPER), a Bitcoin Layer 2 project currently in presale that has raised more than $32.6M at a current token price of $0.0136797.
The project’s core claim, an ambitious one, is to be the first Bitcoin Layer 2 to integrate the Solana Virtual Machine (SVM), theoretically delivering faster smart contract execution than Solana itself while relying on Bitcoin’s security layer.
A Decentralized Canonical Bridge handles BTC transfers, and the architecture targets the three structural weaknesses that have historically limited Bitcoin’s programmability: slow throughput, high fees, and the absence of native smart contracts.
The Iran conflict has already demonstrated how quickly Bitcoin’s on-chain infrastructure can be stressed, a scalability layer has genuine utility context here, not just marketing copy. Staking is live with a high APY on offer.
Visit the Bitcoin Hyper Presale Website Here.
EXPLORE: Best Ethereum wallets for 2026 – CoinSpeaker’s updated guide
next
The post Bitcoin Crashes Below $80K as Iran War Escalates: Green Streak Broken? appeared first on Coinspeaker.
Two law enforcement officers in the Miami-Dade Sheriff’s Office, Jason Smith and Jonathan Santana, have filed a lawsuit against Ben Affleck and Matt Damon’s production company Artists Equity over “The Rip,” the Netflix crime drama directed by Joe Carnahan that launched on the streamer in January. As reported by Entertainment Weekly: “Smith and Santana allege […]
Michael Saylor defended Strategy’s Bitcoin-backed credit model after critics argued that the company’s STRC dividend structure resembled a Ponzi scheme, saying the business is built around monetizing Bitcoin capital gains rather than relying on perpetual equity issuance.
Speaking in an interview shared via X on May 9, Saylor addressed the market reaction to Strategy’s recent earnings call, where the company said it was prepared to sell Bitcoin, if needed, to fund dividends on its STRC preferred instrument. The remark drew attention because Saylor has long been associated with the phrase “never sell your Bitcoin.”
According to Saylor, the more precise formulation is that Strategy does not intend to be a “net seller” of Bitcoin.
“I’m very famous for saying, never sell your Bitcoin. And that’s why the internet went crazy when we said we might sell it,” Saylor said. “But if I was being more precise, I’d say never be a net seller of Bitcoin. It just wouldn’t have been so viral or so catchy to say never be a net seller of Bitcoin.”
Why Strategy Is Not A Bitcoin Ponzi Scheme
The issue became a point of contention after Peter Schiff and other critics suggested that Strategy’s willingness to sell Bitcoin to support STRC dividends exposed weakness in the model. Saylor rejected that framing, saying the company’s balance sheet should not be treated as if its Bitcoin holdings were unusable or worth zero.
“If you had $65 billion worth of something and people wanted to value it at zero, it’s not very good,” he said. “We don’t want the credit rating agencies to think the company has $0 of assets. We want the credit rating agencies to think we have $65 billion of assets.”
Saylor said the core model is straightforward: Strategy issues credit, uses the proceeds to buy Bitcoin, and expects the asset’s long-term appreciation to exceed the cost of the dividend. He compared the structure to a real estate development company raising capital through credit, acquiring land, improving it, and later monetizing the appreciation through sales, rent, or refinancing.
“What we wanna do is we wanna reinforce the business model is we sell credit to make a capital investment in an asset, Bitcoin, digital capital,” Saylor said. “The capital investment accretes over time faster than the dividend. We then monetize the capital gain and we pay the dividend.”
That distinction is central to Saylor’s response to Ponzi allegations. In his view, critics conflate selling common equity to fund dividends with the broader economic structure of the business. He said Strategy historically used MSTR equity, which he described as a derivative of Bitcoin that typically trades at a premium to Bitcoin, to fund dividends. But the company now wants the market to understand it could also use appreciated Bitcoin directly.
Saylor said that does not mean Strategy expects to shrink its Bitcoin position. He argued that even if the company sold Bitcoin for dividend payments, its credit issuance would allow it to buy substantially more Bitcoin than it sells.
“If we sell Stretch, if we issue Stretch credit equal to 2.3% of our Bitcoin holdings, then that means we will be a net buyer of Bitcoin forever, even if we sell Bitcoin to pay the dividend,” he said. “Another point is that if Bitcoin appreciates 2.3% a year, we can pay the dividends forever, right? And continue to grow value, right? And we can do it without selling any common equity.”
He added that Strategy sold $3.2 billion of STRC in April, while the monthly dividend requirement was roughly $80 million to $90 million. In that scenario, he said, the company would effectively be “buying 30 Bitcoin and selling one Bitcoin,” leaving it a net accumulator.
The interview also directly addressed Schiff’s criticism. Saylor said Schiff’s objection begins with a rejection of BTC itself, making it unlikely that he would accept a credit instrument built on top of it.
“Peter thinks Bitcoin’s a Ponzi scheme. Peter is not really a lover of anything in this space,” Saylor said. “Bitcoin is digital capital and we’ve created a digital treasury company by selling equity and credit instruments to buy capital. I think that Bitcoin is going to continue because it represents economic wealth in tokenized form with full property rights for the world.”
Saylor described STRC as a form of “digital credit” designed to strip out some Bitcoin volatility while producing a defined yield. He said Strategy overcollateralizes the instrument, with “for every $5 of Bitcoin” the company selling “$1 of credit.”
“If you don’t acknowledge Bitcoin as legitimate, you’ll never acknowledge any derivative on top of it as legitimate,” he said. “But for those people that believe that Bitcoin is digital capital, as a store of economic wealth in tokenized form, then what we’re doing is very straightforward.”
Since November 2017, Tether has frozen USDT stablecoins across 9,856 addresses, locking up a combined $5.17 billion. Of that, only $602 million, thus roughly 11.6% by value, has ever been unfrozen. The remaining $4.57 billion stays frozen.
DailyCoin analyzed the full freeze and unfreeze history to track how frozen assets move through the system over time.
One-Way Door: The Scale of Tether’s Blacklist
The scale of Tether’s blacklist is larger than most realize.









")